在不同的 Windows 作業系統執行 JBoss AS,有時候會發生沒辦法啟動的問題,原因是比較新的版本,run.bat 會透過 Windows 內建的 findstr.exe 檔案,去判斷現在找到的 JVM 支不支援 -server 這個選項,或者是不是個 64-Bit 的 JVM。問題是,findstr.exe 檔案所在的位置,有時候不知道為什麼並不在 PATH 環境變數之中。
解決方式也很簡單:要嘛把 findstr.exe 複製到一個 PATH 裡頭找得到的路徑,或是把 findstr.exe 的路徑加到 PATH 環境變數裡面,這樣就可以了。
PS. 一般來說,findstr.exe 檔案放在 C:\Windows\System32 目錄之中。
PS2. 另外兩個常見會導致無法執行 JBoss AS 的問題,一個是把 JDK 裝在像 C:\Program Files 這種路徑當中有空白的目錄之中,另一個是沒有設定 JAVA_HOME 環境變數。
2009年12月29日 星期二
2009年12月24日 星期四
NetBeans 攻略 - Tomcat 設定
正常在 Windows 下直接執行 Tomcat,可以正確辨識出中文的 Locale ID,顯示中文訊息:

很奇怪,如果透過 NetBeans 啟動 Tomcat,就會變成亂碼,調整字型也沒有用:

這時候請選取 NetBeans 功能表的 Tools、Servers,在 Tomcat 設定中點選 Platform 標籤頁,在 VM Options 裡面加上以下的設定:
-Duser.language=en -Duser.country=US

這樣就不會有亂碼了:

不過我改用繁體中文的 Locale ID,卻行不通,不知道原因為何?
2009年12月14日 星期一
NetBeans 攻略 - 組態設定
最近比較認真一點使用 NetBeans,所以就會碰到一些問題,必須要想辦法解決:
- 功能表跟對話方塊內容會變亂碼
這個問題有幾個可能,一個是因為 JDK 5 與 JDK 6 對字型 Anti-Aliasing 處理的方式不同,另一個可能是找不到包含中文字的系統字型,所以解決方式也有幾種:
- 如果是用 JDK 6 的話,可以檢查一下有沒有啟用 Clear Type 功能?如果沒有的話,啟用 Clear Type 功能或許就解決了。JDK 6 的 Swing 預設會啟用 Anti-Aliasing 功能,所以 Windows XP 的 Clear Type 也要啟動配合才比較不會有問題。
- 如果是用 JDK 6 的話,也可以試看看在 %JAVA_HOME%\jre\lib\fonts 目錄裡面新增一個 fallback 子目錄,裡面放個有中文字的字型,比方說微軟正黑體。重新啟動 NetBeans 之後,說不定就解決了。不知道為什麼系統明明就有內含中文字的字型,但是 Swing 就是看不到。
- 如果是用 JDK 6,但是前兩種作法都行不通的話,那就改用舊一點的 JDK 6,或是用 JDK 5 試看看,說不定就解決了。JDK 5 預設好像不會啟動 Anti-Aliasing 功能,所以問題比較少,但是字型顯示的時候也會比較醜一點。JDK 6 有些版本的 Swing 問題比較多,比方說 Update 12 與 Update 17,避掉會比較好。
- 還沒想到。
- 想要使用其他語系的介面
如果像我不太習慣中文介面,想要改用英文介面的話,可以在執行 NetBeans 的時候多加一個參數 --locale,後面跟個 Locale ID。比方說,netbeans.exe --locale en_US。注意是兩個減號。
- 功能表跟標籤頁的字體太小
這個問題的解法通常都是在執行 NetBeans 的時候多加一個參數 --fontsize,後面跟個數字,預設值是 11。比方說:netbeans.exe --fontsize 15。注意是兩個減號。不過,設定了之後不見得會有用,因為有些 Swing 的 Look and Feel 沒有寫好,功能表跟其他一些控制項的字體大小都寫死了,這時候用這個參數就沒有用,必須要順便換個寫的比較好的 Look and Feel 才可以。
- Output 視窗的字體太小
這個問題以前的解法通常都是用上面提到的 --fontsize,但是有一個缺點,就是除了 Output 視窗字體變大之外,其他地方的字體也都跟著變大。現在有一個比較好的作法,只要在 Output 視窗裡面按下滑鼠右鍵,就可以更改字體大小,還可以更換好看一點的字體:

如果要動態調整大小,最新的秘技是點一下 Output 視窗,然後按著 Ctrl 鍵不放,把滑鼠滾輪上下推動,就可以調整大小了!

- 更換 Look and Feel
Swing 有趣的地方就是可以更改 Look and Feel。NetBeans 是用 Swing 寫的,所以當然可以換 Look and Feel,換法就是在執行的時候加個 --laf 參數,後面跟個 Look and Feel 的主類別。比方說:netbeans.exe --laf javax.swing.plaf.metal.MetalLookAndFeel。注意是兩個減號。如果像 Metal 與 Nimbus 這種 JDK 內建的 Look and Feel,也可以寫簡寫:netbeans.exe --laf Metal。如果是 3rd-Party 寫的 Look and Feel,記得要把相關 JAR 檔案放到 Class Path。
- 使用 Unicode 編碼
雖然 NetBeans 專案的預設編碼是 UTF-8:

但是 NetBeans 的一些 Wizard 在自動產生 Java 類別的時候,還是會有一些怪怪不太正確的地方,因為在繁體中文的 Windows 底下,編碼其實還是 MS950:

這時候可以考慮使用英文語系加上指定 Unicode 編碼的方式,來解決這個問題,也就是在執行 NetBeans 的時候多加個參數 -J-Dfile.encoding=UTF-8,編碼就會變成 UTF-8:

-J 的意思指的是,後面的參數是要給 JVM 用的,不是給 NetBeans 用的。-Dkey=value 則是一般執行 Java 程式時控制 JVM 環境變數的方式。注意這邊都是一個減號,然後 –J-D 要連在一起。



- 指定 NetBeans 使用的 JDK
如果系統找得到 JDK,NetBeans 就會自動使用找到的那一份。如果想要指定使用特定位置的 JDK,可以在執行 NetBeans 的時候加個 --jdkhome 參數,後面跟著 JDK 的路徑。比方說:netbeans.exe –jdkhome “../../jdk”。注意是兩個減號。
- 指定 NetBeans 存放 Plugin、Update、與組態設定的目錄
NetBeans 預設會把一堆事後下載與更新的檔案,還有一些設定值,放在 Home Directory 裡面,這對我們製作一個 Portable NetBeans 會造成很大的問題。如果想要指定 NetBeans 存放這些檔案的位置,可以在執行 NetBeans 的時候加個 --userdir 參數,後面跟著存放的路徑。比方說:netbeans.exe –-userdir “../../config”。注意是兩個減號。這個目錄也不可以位於 NetBeans 目錄之內。
以上這些參數可以加在 netbeans.exe 後面,也可以固定寫在 NetBeans 的組態設定檔案裡頭,就是 NetBeans 目錄下的 etc/netbeans.config 檔案:
netbeans_default_userdir="../../config"
netbeans_jdkhome="../../jdk"
netbeans_default_options="原有內容 --locale en_US -J-Dfile.encoding=UTF-8"
2009年6月28日 星期日
讀卡機其實很重要
這次除了偽 SSD 之外,我還買了一個可以讀 CF 卡的讀卡機,還有一個可以把 MicroSD 卡轉成 CF 卡的轉接器。
讀卡機是 ATP All-in-One ProMax USB2.0 Reader (黑色),PCHome 有賣:

比較常見的是白色的機種,叫做 ATP ProMax USB2.0 UDMA 讀卡機(58合一),PCHome 一樣有賣:

ATP 好像就只有這兩種讀卡機,白色這一種買卡的時候有些會送,不過這一款不能讀 CF 卡。黑色是之後出的,可以讀 CF 卡,所以我買黑的。而且黑色的不必再接一條醜醜的 USB 線,因為它有一個隱藏式的旋轉接頭。
去年在日本的時候,因為讀卡機換了,所以臨時在日本買了一個 Sanwa 出的 USB 2.0 Multi-Card Reader/Writer,目前已經停產了,Sanwa 網站上有圖:

我的 Transcend 300x 4G CF 卡,如果透過 Sanwa 的讀卡機去讀,速度只有 20 MB/s:
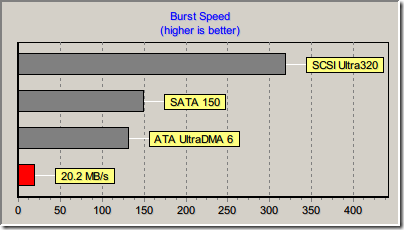
可是如果透過 ATP 的讀卡機去讀,速度可以有 35 MB/s 喔:

這兩個測試是在公司的 HP 四核心機器上進行的。如果是在 X31 上的話,速度也有 31MB/s:

可是這張卡,如果直接接在 X31 裡面的 CF 2 IDE 轉接卡上的話,速度可以有 49MB/s:
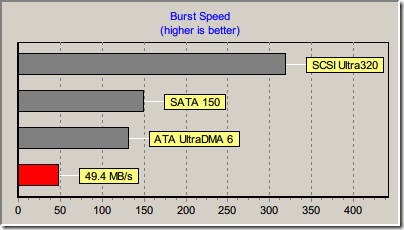
所以,這塊卡的速度應該比 USB 2.0 Controller 與讀卡機的搭配所能提供的頻寬還要高,所以速度應該是被 Controller 與讀卡機限制住了。可是 Sanwa 的讀卡機還真是有點遜,速度只有 ATP 的三分之二。
除了 CF 讀卡機之外,我最近還買了一個玩具,PhotoFast 出的 CR-7000,可以把 SD、MMC、SDHC 等記憶卡轉接成 CF Type II 的轉接卡,PCHome 網站上有圖:

為什麼會買這個東西,是因為 IBM S31 與 X31 上面都直接提供 CF 卡插槽,所以如果要讀 CF 卡的話,就不必再接讀卡機。因為我有幾塊 MiniSD 與 MicroSD 卡,所以我就想,如果透過這個轉接卡,把這些 SD 卡轉成 CF 卡。直接插進這些插槽,那我的 S31 跟 X31 就不必沒事多插一個讀卡機,而且外表也不會突出一塊。
我把 SanDisk 8G MicroSDHC 卡,接上 SanDisk 自己出的 MicroSD 轉 SD 的轉接卡,變成偽 SD 卡之後,再把這個偽 SD 卡插入 CR-7000,變成偽 CF 卡,然後直接插進 X31 的 CF 卡插槽,一切都很順利,也可以正常讀寫。
HD Tach 的速度是很平穩的 1.3 MB/s,實在是遜斃了,可是真正進行一般操作的時候又覺得還好:

如果把 CR-7000 這張偽 CF 卡接上 ATP 的讀卡機去測,速度就變成 8.9 MB/s,幾乎是 7 倍喔:

由此可見,一般 Notebook 內建的記憶卡插槽,有多麼的爛!
如果不透過 CR-7000,直接把偽 SD 卡接上 ATP 的讀卡機去測,速度居然是 20.5 MB/s,是剛剛透過 CR-7000 的 2.3 倍:
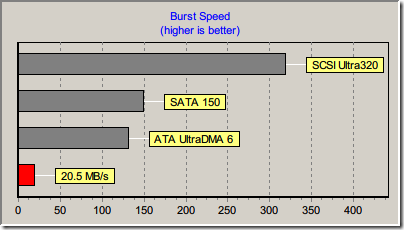
所以,PhotoFast CR-7000 雖然做的不錯,但是一經過它轉換,速度就減半了。
最好笑的是,偽 SD 卡不管怎麼接,接到 Sanwa 的讀卡機,就一整個讀不到。不過這不能怪它,因為它不支援 SDHC。但是把偽 SD 卡插入 CR-7000 變成偽 CF 卡之後,居然就讀的到了!所以 PhotoFast CR-7000 還真的做的蠻不錯的,就是速度慢了一點。
S31 與 X31 這個年代的 Notebook,都有 PCMCIA/Cardbus 介面。不過我不抱太大的希望,因為它走的是低速的 PIO Mode:

看來大家買讀卡機的時候,還是要做一下功課,免得有好卡但是卻沒有好讀卡機。
2009年6月14日 星期日
拿 CF 卡給 IBM X31 當做偽 SSD 使用
因為 X31 跑起來漸漸有點慢了,可是又還沒打算換掉它,所以就要想辦法延長它的壽命。
CPU 不好換,RAM已經是加到飽的 2GB,所以可以換的就只剩硬碟。
因為是 IDE 介面的機種,所以不想再買硬碟來換,現在已經都是 SATA 跟 SATA2 滿街跑了,而且也不好買。
SSD 的話,買 IDE 的 C/P 值好像也不好,選擇也少。而且 SSD 保固跟硬碟差不多,都是兩三年左右,貴的 SLC 買不起,便宜的 MLC 據說會頓頓的。
百般考慮之後,我決定買 SLC 的 CF 卡來當偽 SSD 使用,因為網路上參考資料很多,小一點的 SLC CF 卡也比較買得起,而且 CF 卡是終身保固(雖然這個終身各家廠商解讀都不同),以後不用還可以給 FiFi 的單眼相機使用,所以就是 CF 卡了!
決定了之後,就要開始張羅材料:
- SLC CF 卡
- CF 2 IDE 轉接卡
CF 卡網路上都說要速度越快越好,高速卡才會支援所謂的 Ultra DMA,但是價格也越貴。266x 或 300x 速度,8G 左右的要三千左右,16G 要六七千,4G 好像幼小了點。另外,一般標示的都是讀取的速度,寫入的速度會差一些,甚至也有差很多的!
而且 CF 卡一般會被辨識成「卸除式硬碟」、「Removable Device」,有些卡會支援「Fixed Mode」,有些卡要送回去改才可以。如果想要安裝作業系統,就得被辨識成 Fixed Mode 才可以。
Fixed Mode 倒底長怎樣?就像底下這樣,作業系統跟應用程式會把它當作 Hard Disk,而不是一般插上大姆哥之後的 Removable Device:
做了一下功課之後,我在 PCHome 買了一塊 Transcend (創見) 300x 8G 的 CF 卡,因為據說:
- Transcend 不管 266x 或是 300x 的 CF 卡都可以自動被辨識成 Fixed Mode。
- Transcend 80x (與以下) 還有 266x (與以上) 的 CF 卡,都是 SLC 的,寫入速度很快,不會有 MLC 寫入頓頓的問題。
- Transcend 維修蠻方便的...。
其實,SanDisk 在網路上品質口碑更好,但是也因為這樣,據說有一堆假貨,所以後來代理商的終身保固規定就變得很麻煩,而且也沒有像 Transcend 那種門市直營店,送修也不方便。另外一點更重要,就是網路上找不到肯定的答案,說明 Extreme IV 到底可不可以自動被辨識為 Fixed Mode。所以,我才會買 Transcend 的 CF 卡。
至於 CF 2 IDE 轉接卡,網拍上蠻多的,結果我買了三種:
Addonics 的 AD44MIDE2CF 在網路上好像還蠻出名的,特色是可以插兩塊 CF 卡,Addonics 網站上有圖片:

這塊轉接卡我雖然買的很早,不過最後卻沒用在 X31 上,因為 X31 可以很方便地抽插 2.5 吋的硬碟,但是如果要直接插大小差太多的轉接卡的話,就得將整個 X31 解體一大半,我覺得太累了。後來我把這塊轉接卡插到我的 IBM S31 裡頭,因為 S31要換硬碟一定要拆機,但是不難拆。我還買了一塊 Transcend 300x 4G 的 CF 卡要給 S31 使用,只不過 S31 似乎真的有點舊了,連輕薄短小的 SLAX 都跑的怪怪的,所以我後來就放棄 S31 的改裝工作,專心在 X31 上。
Uptech 就是登昌恆啦!UTN840I 是一塊 Dual CF to 44-Pin IDE 轉接卡,良興電子有圖片:

這一塊卡的特色就是:
- 它可以插兩塊 CF 卡。所以開機可以用一塊 SLC CF 卡,資料可以放在另外一塊慢一點的 MLC CF 卡。
- 它做成 2.5 吋 IDE 硬碟的外型,尺寸大小跟接頭都很棒。Perfectly Match!
- 它的小缺點就是,硬碟兩側並沒有做螺絲孔。有些 Notebook 會有些小東西鎖在硬碟兩側方便抽取,這塊卡就不能鎖這些東西。
所以,目前我的 X31 用的就是這一塊轉接卡。一開始我只有一塊 8G 的卡,FiFi 很好心的給了我一塊 Kingston 1G 的 CF 卡,所以我就把兩塊卡一起插進去使用,後來發現這是個錯。
一開始一切都很順利,但是很奇怪,偶爾 X31 會不理我,我想這就是網友所謂的「頓頓的」吧!可是我買的是 300x SLC 的 CF 卡耶,怎麼會這樣?
找了一下資料,有個大陸網友也有類似的問題,他發現他的 CF 卡只有衝到 Ultra DMA Mode 2,而不是更高的 Mode 4、5、或是 6。我的也是:Device 0 就是 Transcend 300x 8G CF 卡,Device 1 是 Kingston 連倍數都沒標的 1G CF 卡。

所以,我居然只有衝到 Ultra DMA Mode 2,而且還有一個 PIO Mode 的拖油瓶!
根據網路上找到的 CF 卡規格定義, CF 卡的速度極限:
- CF spec 2.0: PIO Mode 5/6 (max 16MB/sec)
- CF spec 3.0: UDMA mode 4 (max 66MB/sec)
- CF spec 4.0: UDMA mode 5 (max 100MB/sec)
- CF spec 4.1: UDMA mode 6 (max 133MB/sec)
看起來 PIO Mode 真的蠻慢的。
根據那個大陸網友找到的作法,我把 Primary IDE 的驅動程式移除,然後重新開機,讓 Windows 重抓一次。測試的結果證實沒用,所以後續甚至還可以改 Registry 來強迫設為 Ultra DMA Mode 5 我就更懶得測了!
PIO Mode 那塊卡本來就不是重點,所以我想的是,有沒有機會讓 Ultra DMA Mode 2 變成 Mode 4、5、或是 6。網路上也有人的轉接卡不夠好,所以速度上不去。
又在網路上找了一陣子,發現有一塊轉接卡強調它可以支援到 Ultra DMA 5,就是伽利略的 CFIDE44ADP 這一塊,3Ctown 有圖片:

這塊卡的特色是:
- 雖然包裝上標的是支援 Ultra DMA Mode 5,但是網頁上寫的是 Ultra DMA 6。
- 這塊轉接卡可以直接插著用,也可以加上一個外殼封裝成一個 2.5 吋的 IDE 硬碟。
- 它的硬碟外殼兩側有著一般正常硬碟的螺絲孔,可以方便一般 Notebook 加些外掛。
不過,我後來沒有使用這塊卡,因為它做的有點薄,所以我試了很久,我沒有辦法很準確地透過方便的抽插方式,把這個硬碟裝進 X31,一定要把 X31 大卸八塊才可以。不過這件事我沒把握,所以我後來放棄了。
後來,因為 S31 改裝不順,所以就多了一塊 Transcend 300x 4G CF 卡。與其放著外接,不如直接塞進 X31,一方面省了一個外接讀卡機、少佔一個 USB 插槽,也可以讓我的 X31 多個 4GB 的空間。
裝了之後,有趣的事情發生了:我的 Device 0 跟 Device 1 都變成 Ultra DMA Mode 4!

而且,那種頓頓的感覺也不見了!
這件事告訴我們:不要把兩個速度差太多的 CF 卡放在一起,這樣會讓好的卡表現不出好成績!
到底拿 CF 卡做偽 SSD 有多快?或是比硬碟快多少?
我忘了測硬碟的速度,就把它拆下來了。不過,我有測 8G CF 卡的速度。從 HD Tach 來看,大概是 47MB/s:

而且一直很平順:

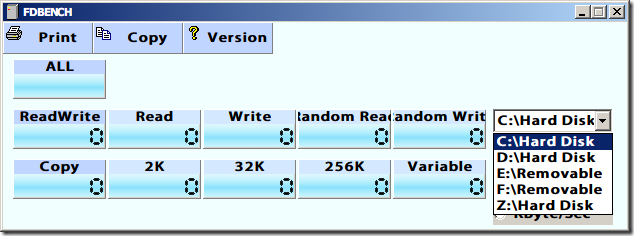
FDBENCH 有讀寫的數據:
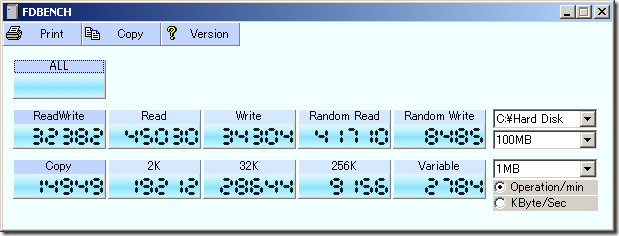
雖然有 1、4、10、20、40MB 這四種大小的測試,不過結果都差不多。不管是 Sequential Read 或是 Random Read 大概都可以有個 40MB/s,Sequential Write 可以有個 30MB/s 以上,但是 Random Write 就不行了,只有 8MB/s。
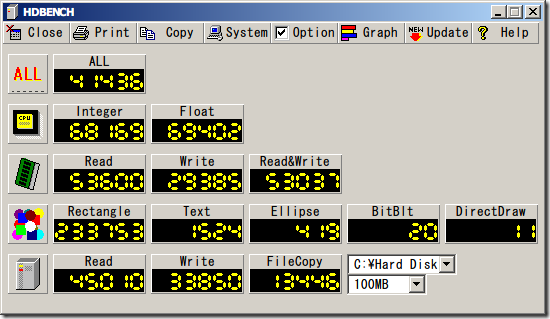
HDBENCH 的數據如下:Read 也是 45MB/s,Write 是 33MB/s 左右。
HD Tune 的話剛開始不知道為什麼掉下來,但是平均還是接近 40MB/s:

所以其實各種軟體測出來的數據都差不多,重點是,感覺上 X31 變快了一些喔!這才是重點啦!
2009年3月14日 星期六
JDK 6 Update 12 的問題
上課的時候,因為沒有包袱,我總是習慣用最新版本的軟體。不過,這次踢到鐵板了!
我這次原先想要使用 NetBeans 6.5 + GlassFlass V2.1 Final Build 來上課,因為 JDK 正好出了 JDK 6 Update 12,我就一起用上了。結果,我在 NetBeans 裡頭完全沒辦法定義新的 Server。選了 Tools、Servers 之後,可以看到底下這個畫面:

可是按下 Add Server... 按鈕,完全沒有反應。不, NetBeans 右下角有一顆一閃一閃的小紅球!

按下 Close 按鈕關掉 Servers 視窗,再點兩下小紅球,才知道出了 NullPointerException:

我本來以為,這或許是因為我習慣用 ZIP 版本的 NetBeans,會不會改用 Setup 程式安裝的版本,就不會有這個問題。試了之後發覺不是,Setup 版本雖然看得到內建的 GlassFish,但是一樣無法讓我自己新增 Server。
星期五的時候,在 JavaTWO009 的會場碰到 koji,我知道 koji 對 NetBeans 跟 GlassFish 都很有研究,就跟他討教了一下。koji 說他沒碰過這個問題,但是他建議我可以試看看換掉 JDK 6 Update 12,因為他說也有人在抱怨 JDK 6 Update 12 讓有些原先可以正常運作的 Swing 程式掛掉。
回家之後馬上試了一下,把 JDK 換成 JDK 6 Update 11 的版本,真的就 OK 了!Add Server Instance 的畫面就出現了!

這件事告訴我們:換 JDK 是真的有可能會讓程式掛掉的喔!
2008年10月24日 星期五
Google JMesa、Flying Saucer、iText 的中文問題
Google JMesa 是一個功能蠻強大的 HTML Data Grid,不只提供分頁、篩選等功能,還可以將結果匯出成 Excel 或 PDF 檔案。之前上課的時候我在 Lab 裡面用到,不過因為處理的都是英文資料,所以看不出問題,這兩天有位學員問我中文亂碼怎麼處理,我才意識到有這個問題。
以 JMesa 本身提供的範例來說,我看了一下 WEB-INF\lib,看到 iText 的 JAR 檔案,我本來以為只要按照調整 iText 的方式就可以成功,所以就放心了。結果我 Trace了一下Source Code:
1. BasicPresidentController 會呼叫 TableFacade 的 render 方法
2. TableFacade 的 render 方法會長個 PdfViewExporter,呼叫 export 方法
3. PdfViewExporter 的 export 方法會長個 org.xhtmlrenderer.pdf.ITextRenderer,呼叫 createPDF 方法
這時問題就來了,JMesa 沒有直接用 iText,將結果輸出為 PDF,這樣要處理的細節比較多,比較累。因為 JMesa 可以產生 HTML,透過 CSS 與 JavaScript 做出其他功能,所以它就利用 Flying Saucer 這個封裝 iText 的 HTML/XHTML Parser,也就是上面看到的 xhtmlrenderer 相關套件,把畫面上看到的 HTML+CSS 透過 Flying Saucer 底層封裝的 iText 去產生 PDF:
JMesa -> HTML+CSS -> Flying Saucer -> iText -> PDF
所以,我們不能直接用修改 iText 的方式去解決中文,而要用 Flying Saucer 的方式去解決,不過底層一樣是 iText,所以其實改法大同小異,網路上搜尋一下,可以找到底下的做法:
import com.lowagie.text.pdf.BaseFont;
...
ITextRenderer renderer = new ITextRenderer();
ITextFontResolver resolver = renderer.getFontResolver();
resolver.addFont(
"C:/WINDOWS/Fonts/中文字型名稱.TTF",
BaseFont.IDENTITY_H,
BaseFont.NOT_EMBEDDED 或 BaseFont.EMBEDDED
);
不過呢,這個做法不 Work。
解決這個問題,要從上面箭頭的流程由右往左一步一步解決:
iText -> PDF
iText 要能夠產生中文 PDF,第一要有它可以處理的中文字型,目前最常用的 Unicode 編碼TrueType 字型不見得可以順利載入,因為 iText 對 TrueType Collection 與 OpenType 支援的程度似乎還沒有很好,所以要先找出 iText 可以用的中文字型,免得明明一切步驟都對,就敗在字型這一關。幾乎每台裝了 Office 的 Windows 電腦都會有 Arial Unicode MS (arialuni.ttf) 這個字型,iText 也認得,所以我就以這個字型做示範。
第二步,要試出正確的編碼。有些中文字型可以用 BaseFont.IDENTITY_H,有些可以用 UniCNS-UCS2-H,要試過才知道。Arial Unicode MS 用的是 BaseFont.IDENTITY_H,但是像 Adobe Reader 附贈的中黑體就要用 UniCNS-UCS2-H。
第三步,要有 iTextAsian.jar 檔案,跟 iText 的 JAR 檔案放在一起。Flying Saucer 跟 JMesa 內含的 iText 版本比較舊,目前最新是 2.1.x 版,但是跟 Flying Saucer 搭配會有問題,因為 Flying Saucer 會用到新版 iText 已經不提供的 API。所以,我把 iText 的 JAR 檔案換成 2.0.8 版,2.1 之後的版本就不行了。
Flying Saucer -> iText -> PDF
Flying Saucer 目前最新是 Release 8 – Second Code Drop (R8pre2) 版本,JMesa 內含的舊了一點,所以我也更新了。
我準備了一個簡單的 XHTML 檔案:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>中文測試</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<style type="text/css">
name
{
font-family: "Arial Unicode MS";
color: blue;
font-size: 48;
}
</style>
</head>
<body>
<name>名偵探小怪獸</name>
</body>
</html>
然後模仿網站上找到的範例,直接寫一個 Java 類別去產生 PDF 檔案:
import java.io.*;
import org.xhtmlrenderer.pdf.*;
import com.lowagie.text.pdf.*;
public class Test
{
public static void main(String[] args)
{
try
{
String inputFile = "test.xhtml";
String url = new File(inputFile).toURI().toURL().toString();
String outputFile = "test.pdf";
OutputStream os = new FileOutputStream(outputFile);
ITextRenderer renderer = new ITextRenderer();
ITextFontResolver resolver = renderer.getFontResolver();
resolver.addFont(
"C:/Windows/Fonts/arialuni.ttf",
BaseFont.IDENTITY_H,
BaseFont.EMBEDDED);
renderer.setDocument(url);
renderer.layout();
renderer.createPDF(os);
os.close();
}
catch (Exception e)
{
System.out.println(e.getMessage());
}
}
}
這樣就成功了:


到目前為止,跟網路上找到的解法,差別如下:
- 網路上只說明 Java 程式怎麼加入中文字型,可是一般卻沒有說明必須透過 CSS 去指定使用這個字型,所以雖然加入字型,但是卻沒有被使用到,所以還是會一直看到中文亂碼。
- 網路上沒有提醒要加入 iTextAsian.jar 檔案。
另外,其實除了 addFont 方法之外,還有 addFontDirectory 方法,可以一口氣把某個目錄所有字型都註冊。不過這個方法只要一碰到問題就執行不下去,比方說要嵌入不准嵌入的字型,所以不建議貿然使用。
HTML+CSS -> Flying Saucer -> iText -> PDF
接下來,要解決 JMesa 匯出 PDF 會產生亂碼的問題。既然 Flying Saucer 已經可以順利產生中文 PDF,JMesa 也可以在 Browser 畫面上看到中文,那我就先把網頁畫面另存新檔,改一下剛剛的 Java 類別,看看能不能 Work。
網頁內容如下,重點是加入 css 目錄內的 jmesa-pdf.css 這個檔案,因為那是 JMesa 餵給 Flying Saucer 產生 PDF 要使用的 CSS:
<html>
<head>
<link rel="stylesheet" type="text/css" href="jmesa-pdf.css"></link>
<title>JMesa</title>
</head>
<body>
...
<tr id="basic_row1" class="odd"
onmouseover="this.className='highlight'"
onmouseout="this.className='odd'" >
<td><a href="http://www.whitehouse.gov/history/presidents/">喬治</a></td>
<td>Washington</td>
<td>1789-1797</td>
<td>Soldier, Planter</td>
<td>02/1732</td>
</tr>
...
</body>
</html>
記得 iText -> PDF 要注意的三件事,也不要忘了 Java 程式裡面註冊的字型,HTML+CSS 裡面必須要用到。所以我們修改一下 jmesa-pdf.css 檔案裡面顯示 Table 內容的設定:
.jmesa .odd td, .jmesa .even td {
/* font-family: verdana, arial, helvetica, sans-serif; */
font-family: "Arial Unicode MS";
/* font-size: 11px; */
font-size: 16;
padding: 2px 3px 2px 3px;
}
這麼一來,我們就可以將 JMesa 顯示的中文畫面手動地拿給 Flying Saucer 產生中文 PDF。做這件事的目的,是要確定 JMesa 產生的 HTML+CSS 究竟是否正確,不要改了半天,才發現源頭根本就出了問題。

JMesa -> HTML+CSS -> Flying Saucer -> iText -> PDF
最後一步,就是要想辦法把前一步自動化,這部份花了我最多時間。
首先,因為這一步要改一下 JMesa 的 Source Code,所以請解開 JMesa 的 Source Code,跟 JMesa 的範例程式放在一起。又因為要重新 Build 出 JMesa,也要更新 iText 與 Flying Saucer,所以請下載以下的 Library:
- iText 2.0.8:原因如上
- iTextAsian.jar:原因如上
- Flying Saucer R8pre2:原因如上
- JMesa 2.3.4:JMesa 範例裡面放的 JMesa JAR 檔案,請刪除,因為我們要修改它的 Source
- Spring Framework 2.5.5:換掉範例裡面 2.0.2 版的 Spring 與 AOP 模組
- Struts 2.0.12:要用到 XWork 的 JAR 檔案
- Java Portlet API:我從 Apache Pluto 裡面取得
antlr-2.7.6.jar
asm-2.2.jar
cglib-nodep-2.1_3.jar
commons-beanutils-1.7.0.jar
commons-collections-3.0.jar
commons-dbcp-1.2.jar
commons-digester-1.5.jar
commons-io-1.3.jar
commons-lang-2.4.jar
commons-pool-1.2.jar
core-renderer.jar (新版的 Flying Saucer)
dom4j-1.6.1.jar
groovy-1.0.jar
hibernate-3.2.1.ga.jar
hsqldb-1.8.0.1.jar
iText-2.0.8.jar (新版的 iText)
iTextAsian.jar (新增)
jcl104-over-slf4j-1.4.3.jar
jexcel-2.6.6.jar
jstl-1.1.2.jar
jta-1.0.1B.jar
log4j-1.2.13.jar
minium.jar
poi-3.0-FINAL.jar
portlet-api-1.0.jar (新增,取自 Pluto)
servlet-api-2.4.jar
sitemesh-2.2.1.jar
slf4j-api-1.4.3.jar
slf4j-log4j12-1.4.3.jar
spring-test.jar (新增,取自新版的 Spring Framework,取代 spring-mock-1.2.6.jar)
spring-webmvc-portlet.jar (新增,取自新版的 Spring Framework)
spring-webmvc.jar (新增,取自新版的 Spring Framework)
spring.jar (新版的 Spring Framework)
standard-1.1.2.jar
tagsoup-1.1.3.jar
xercesImpl-2.6.1.jar
xwork-2.0.6.jar (新增,取自 Struts)
第二步,先能夠正確輸入與顯示中文資料。
修改 WEB-INF/presidents.txt 檔案,加入一些中文人名,這樣測試的時候就不必每次輸入中文,也可以順便測試中文顯示是否正確:
"喬治","Washington","Father of His Country", ...
"約翰","Adams","Atlas of Independence", ...
"Thomas","Jefferson","Man of the People, Sage of Monticello", ...
...重新執行 JMesa 的範例,卻發現一樣顯示亂碼。這很簡單,應該是 JMesa 範例內的 JSP 檔案 Character Encoding 沒有設定 UTF-8,所以我就開始進行以下的動作。
修改 decorators/main.jsp 檔案,加入 UTF-8 設定:
<%@ taglib uri="sitemesh-decorator" prefix="decorator" %>
<%@ page contentType="text/html; charset=UTF-8" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...>
<html>
...
</html>
修改 jsp/*.jsp 檔案,加入 UTF-8 設定。以 basic.jsp 為例:
<%@ page contentType="text/html; charset=UTF-8" %>
<html>
<head>
<title>Basic JMesa Example</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
...
</html>
改到這邊,我就很高興的重新執行,結果可以看到中文,太好了!
搞笑的是,輸入中文的時候可以看到中文,但是在 Worksheet 範例按下 Save 按鈕的時候,原本正確的中文卻會變成亂碼。這應該是 HttpServletRequest 物件 Character Encoding 沒有設定 UTF-8。
修改 org.jmesa.web.HttpServletRequestWebContext 類別的 Constructor,加入 UTF-8 設定:
public HttpServletRequestWebContext(HttpServletRequest request)
{
try
{
request.setCharacterEncoding("UTF-8");
}
catch (Exception e)
{
e.printStackTrace();
}
this.request = request;
}
到這個階段,JMesa 的範例才能夠正確輸入與顯示中文 (喬治與約翰是從檔案讀入的資料,湯瑪士是手動輸入的資料):

我本來以為這一步不是那麼重要,所以就先去改第三步,結果反而走了很多冤枉路。Jakarta Commons Lang 如果沒有正確設定 Character Encoding,StringUtils.escapeXml 方法就不能正確運作,會把正確的內容翻成亂碼。所以這一步一定要先改好才行!
第三步,能夠匯出中文 PDF 檔案。
修改 org.jmesa.view.pdf.PdfViewExporter 類別的 export 方法:
public void export() throws Exception
{
byte[] contents = view.getBytes();
responseHeaders(response);
...
ITextRenderer renderer = new ITextRenderer();
ITextFontResolver resolver = renderer.getFontResolver();
resolver.addFont(
"C:/Windows/Fonts/arialuni.ttf",
BaseFont.IDENTITY_H,
BaseFont.EMBEDDED
);
DocumentBuilder builder =
DocumentBuilderFactory.newInstance().newDocumentBuilder();
InputStream is = new ByteArrayInputStream(contents);
Document doc = builder.parse(is);
renderer.setDocument(doc, getBaseUrl());
renderer.layout();
renderer.createPDF(response.getOutputStream());
}
重新執行之後,不只可以正確輸入與顯示中文,在 Basic 範例按下匯出 PDF 的按鈕,還可以看到正確的中文 PDF 自動產生:

總算是大功告成。
不只是 PDF 檔案,連 Excel 都不會有問題喔:

訂閱:
意見 (Atom)